Note
Last update 04/05/2021
Case studies
This page describes the model configurations used in research publications based on Superflex and SuperflexPy.
Dal Molin et al., 2020, HESS
This section describes the implementation of the semi-distributed hydrological model M02 presented in the article:
Dal Molin, M., Schirmer, M., Zappa, M., and Fenicia, F.: Understanding dominant controls on streamflow spatial variability to set up a semi-distributed hydrological model: the case study of the Thur catchment, Hydrol. Earth Syst. Sci., 24, 1319–1345, https://doi.org/10.5194/hess-24-1319-2020, 2020.
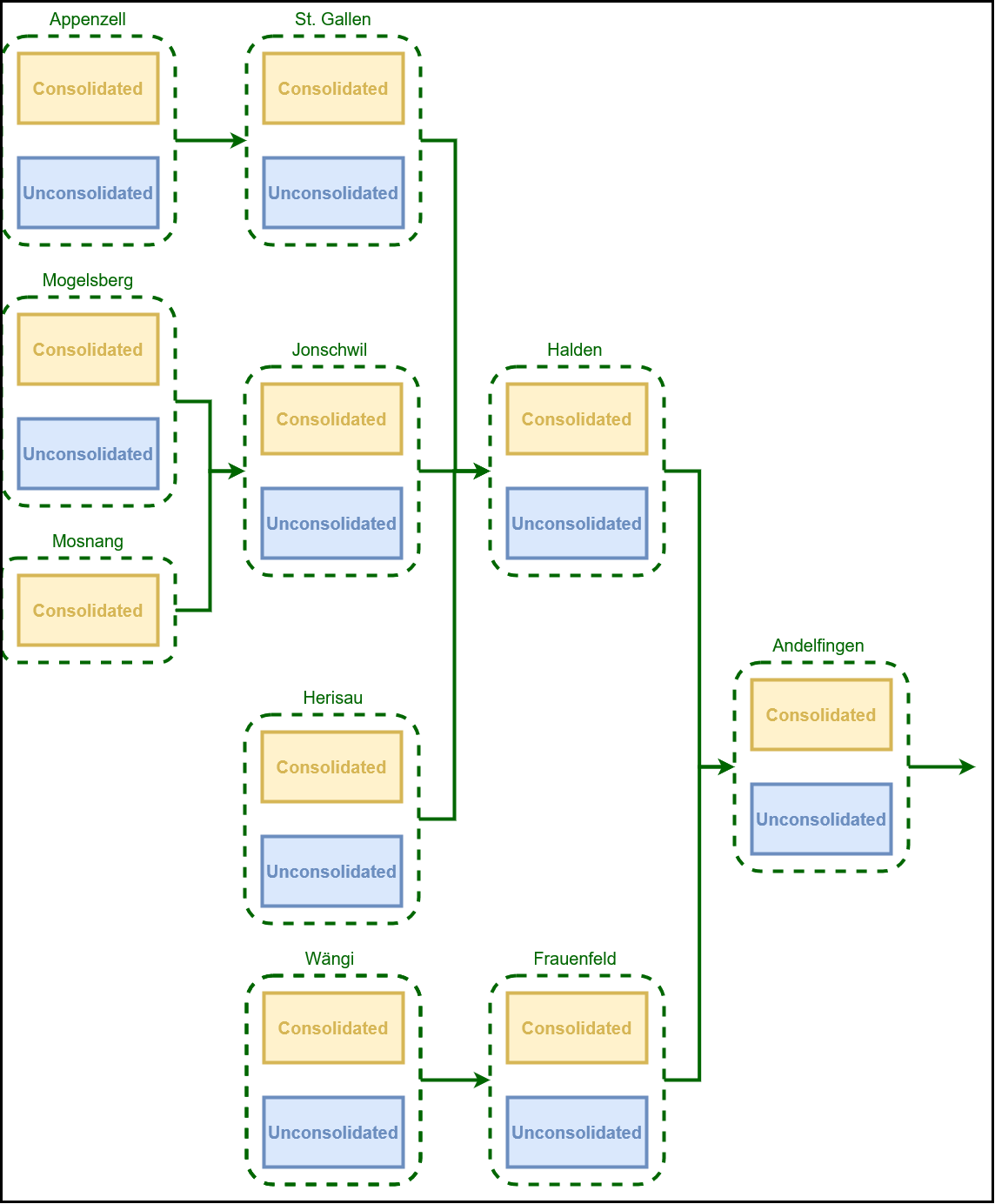
In this application, the Thur catchment is discretized into 10 subcatchments and 2 hydrological response units (HRUs). Please refer to the article for the details; here we only show the SuperflexPy code needed to reproduce the model from the publication.
Model structure
The two HRUs are represented using the same model structure, shown in the figure below.
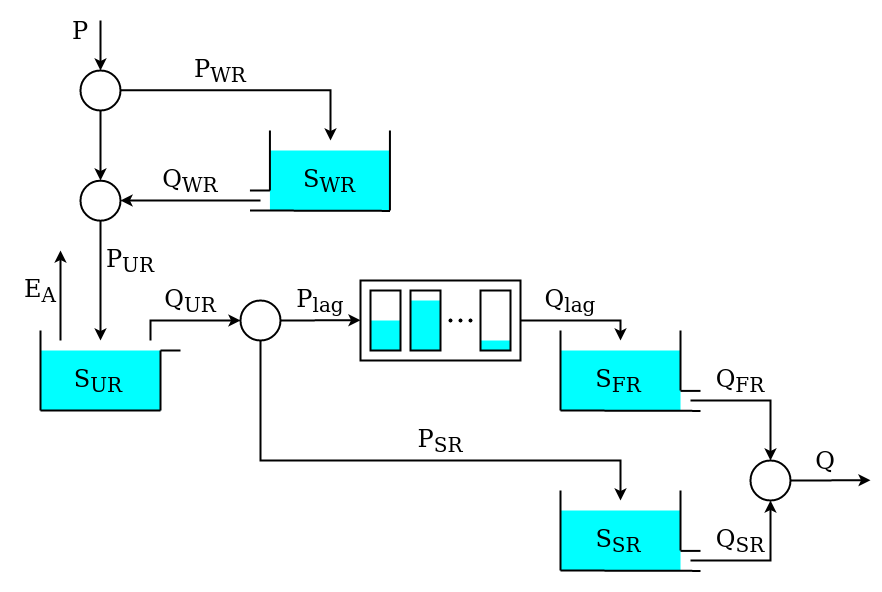
This model structure is similar to HYMOD; its implementation using SuperflexPy is presented next.
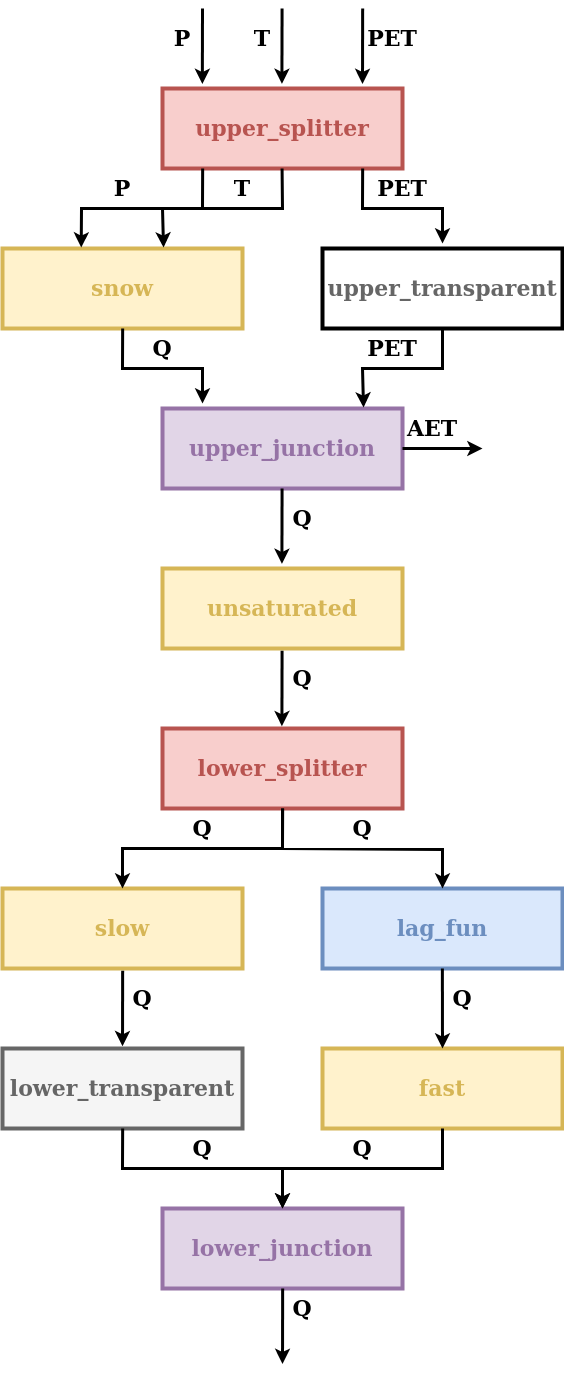
This model structure includes a snow model, and hence requires time series of temperature as an input in addition to precipitation and PET. Inputs are assigned to the element in the first layer of the unit and the model structure then propagates these inputs through all the elements until they reach the element (snow reservoir) where they are actually needed. Consequently, all the elements upstream of the snow reservoir have to be able to handle (i.e. to input and output) that input.
In this model, the choice of temperature as input is convenient because temperature is required by the element appearing first in the model structure.
In other cases, an alternative solution would have been to design the snow reservoir such that the temperature is one of its state variables. This solution would be preferable if the snow reservoir is not the first element of the structure, given that temperature is not an input commonly used by other elements.
The discretization of the Thur catchment into units (HRUs) and nodes (subcatchments) is represented in the figure below.
Initializing the elements
All elements required for this model structure are already available in SuperflexPy. Therefore they just need to be imported.
1from superflexpy.implementation.elements.thur_model_hess import SnowReservoir, UnsaturatedReservoir, HalfTriangularLag, PowerReservoir
2from superflexpy.implementation.elements.structure_elements import Transparent, Junction, Splitter
3from superflexpy.implementation.root_finders.pegasus import PegasusPython
4from superflexpy.implementation.numerical_approximators.implicit_euler import ImplicitEulerPython
Elements are then initialized, defining the initial state and parameter values.
1solver = PegasusPython()
2approximator = ImplicitEulerPython(root_finder=solver)
3
4upper_splitter = Splitter(
5 direction=[
6 [0, 1, None], # P and T go to the snow reservoir
7 [2, None, None] # PET goes to the transparent element
8 ],
9 weight=[
10 [1.0, 1.0, 0.0],
11 [0.0, 0.0, 1.0]
12 ],
13 id='upper-splitter'
14)
15
16snow = SnowReservoir(
17 parameters={'t0': 0.0, 'k': 0.01, 'm': 2.0},
18 states={'S0': 0.0},
19 approximation=approximator,
20 id='snow'
21)
22
23upper_transparent = Transparent(
24 id='upper-transparent'
25)
26
27upper_junction = Junction(
28 direction=[
29 [0, None],
30 [None, 0]
31 ],
32 id='upper-junction'
33)
34
35unsaturated = UnsaturatedReservoir(
36 parameters={'Smax': 50.0, 'Ce': 1.0, 'm': 0.01, 'beta': 2.0},
37 states={'S0': 10.0},
38 approximation=approximator,
39 id='unsaturated'
40)
41
42lower_splitter = Splitter(
43 direction=[
44 [0],
45 [0]
46 ],
47 weight=[
48 [0.3], # Portion to slow reservoir
49 [0.7] # Portion to fast reservoir
50 ],
51 id='lower-splitter'
52)
53
54lag_fun = HalfTriangularLag(
55 parameters={'lag-time': 2.0},
56 states={'lag': None},
57 id='lag-fun'
58)
59
60fast = PowerReservoir(
61 parameters={'k': 0.01, 'alpha': 3.0},
62 states={'S0': 0.0},
63 approximation=approximator,
64 id='fast'
65)
66
67slow = PowerReservoir(
68 parameters={'k': 1e-4, 'alpha': 1.0},
69 states={'S0': 0.0},
70 approximation=approximator,
71 id='slow'
72)
73
74lower_transparent = Transparent(
75 id='lower-transparent'
76)
77
78lower_junction = Junction(
79 direction=[
80 [0, 0]
81 ],
82 id='lower-junction'
83)
Initializing the HRUs structure
We now define the two units that represent the HRUs.
1consolidated = Unit(
2 layers=[
3 [upper_splitter],
4 [snow, upper_transparent],
5 [upper_junction],
6 [unsaturated],
7 [lower_splitter],
8 [slow, lag_fun],
9 [lower_transparent, fast],
10 [lower_junction],
11 ],
12 id='consolidated'
13)
14
15unconsolidated = Unit(
16 layers=[
17 [upper_splitter],
18 [snow, upper_transparent],
19 [upper_junction],
20 [unsaturated],
21 [lower_splitter],
22 [slow, lag_fun],
23 [lower_transparent, fast],
24 [lower_junction],
25 ],
26 id='unconsolidated'
27)
Initializing the catchments
We now assign the units (HRUs) to the nodes (catchments).
1andelfingen = Node(
2 units=[consolidated, unconsolidated],
3 weights=[0.24, 0.76],
4 area=403.3,
5 id='andelfingen'
6)
7
8appenzell = Node(
9 units=[consolidated, unconsolidated],
10 weights=[0.92, 0.08],
11 area=74.4,
12 id='appenzell'
13)
14
15frauenfeld = Node(
16 units=[consolidated, unconsolidated],
17 weights=[0.49, 0.51],
18 area=134.4,
19 id='frauenfeld'
20)
21
22halden = Node(
23 units=[consolidated, unconsolidated],
24 weights=[0.34, 0.66],
25 area=314.3,
26 id='halden'
27)
28
29herisau = Node(
30 units=[consolidated, unconsolidated],
31 weights=[0.88, 0.12],
32 area=16.7,
33 id='herisau'
34)
35
36jonschwil = Node(
37 units=[consolidated, unconsolidated],
38 weights=[0.9, 0.1],
39 area=401.6,
40 id='jonschwil'
41)
42
43mogelsberg = Node(
44 units=[consolidated, unconsolidated],
45 weights=[0.92, 0.08],
46 area=88.1,
47 id='mogelsberg'
48)
49
50mosnang = Node(
51 units=[consolidated],
52 weights=[1.0],
53 area=3.1,
54 id='mosnang'
55)
56
57stgallen = Node(
58 units=[consolidated, unconsolidated],
59 weights=[0.87, 0.13],
60 area=186.6,
61 id='stgallen'
62)
63
64waengi = Node(
65 units=[consolidated, unconsolidated],
66 weights=[0.63, 0.37],
67 area=78.9,
68 id='waengi'
69)
Note that all nodes incorporate the information about their area, which
is used by the network to calculate their contribution to the total outflow.
There is no requirement for a node to contain all units. For example, the unit
unconsolidated is not present in the Mosnang subcatchment. Hence, as
shown in line 50, the node mosnang is defined to contain only the unit
consolidated.
Initializing the network
The last step consists in creating the network that connects all the nodes previously initialized.
1thur_catchment = Network(
2 nodes=[
3 andelfingen,
4 appenzell,
5 frauenfeld,
6 halden,
7 herisau,
8 jonschwil,
9 mogelsberg,
10 mosnang,
11 stgallen,
12 waengi,
13 ],
14 topology={
15 'andelfingen': None,
16 'appenzell': 'stgallen',
17 'frauenfeld': 'andelfingen',
18 'halden': 'andelfingen',
19 'herisau': 'halden',
20 'jonschwil': 'halden',
21 'mogelsberg': 'jonschwil',
22 'mosnang': 'jonschwil',
23 'stgallen': 'halden',
24 'waengi': 'frauenfeld',
25 }
26)
Running the model
Before the model can be run, we need to set the input fluxes and the time step size.
The input fluxes are assigned to the individual nodes (catchments).
Here, the data is available as a Pandas DataFrame, with columns names P_name_of_the_catchment,
T_name_of_the_catchment, and PET_name_of_the_catchment.
The inputs can be set using a for loop
1for cat, cat_name in zip(catchments, catchments_names):
2 cat.set_input([
3 df['P_{}'.format(cat_name)].values,
4 df['T_{}'.format(cat_name)].values,
5 df['PET_{}'.format(cat_name)].values,
6 ])
The model time step size is set next. This can be done directly at the network level, which automatically sets the time step size to all lower-level model components.
1thur_catchment.set_timestep(1.0)
We can now run the model and access its output (see Semi-distributed model with multiple nodes for details).
1output = thur_catchment.get_output()